Bias in NLP algorithms and why you should care
27 February 2020
Recently I presented my work in FAT* 2020 , the premier academic conference on AI ethics (which also announced a name change to FAccT). Most of the discussions, topics, and papers were on algorithmic fairness, privacy and accountability, AI explainability, issues of AI commercial applications, theoretical and sociological investigations, as well as analysis of regulatory frameworks. Indeed, the scientists at the conference were able to interact with the broad field of AI Ethics. Given that this year’s conference had a special social science track, interdisciplinarity reigned at the conference, and perspectives from various fields were heard.
This scientific diversity, however, brought to light some of the difficulties of working across disciplines. Topics that were really important for social scientists, some of which have been discussed and investigated for decades or centuries, concerning political power, forms of justice, and social structures, were received as revolutionary by the computer scientists. On the other hand social scientists did not notice some of the more formal algorithmic issues that computer scientists focus on, some of which may have seemed highly detached from the social reality. With the exception of commercial AI applications and cases of discrimination or privacy violations, where injustice and algorithmic issues are entangled, other cases of biases seemed distant and potentially unimportant.
You see, NLP research lives partly in its own scientific universe. Mapping words to numbers, searching for meanings in vector spaces, using information theory and statistical tools to comprehend and generate language, all seem quite distant to the issues an individual faces in their everyday life. And more importantly, when NLP algorithms suffer from serious biases, it is really difficult for someone to locate them, describe them, and bring awareness to them. In contrast to other algorithms used for job application filtering, predicting recidivism, policing, or insurance modeling, text-based algorithms are usually implemented in systems that are highly opaque or are deployed in applications not directly related to algorithmic decision making. For example, if a search engine uses NLP and results in biased search results, this is a very serious issue. Tracing, quantifying it, and getting access to a proprietary algorithm to understand why it is so is practically impossible. Similarly, tracing that a translation engine carries gender biases brings less attention than hearing that an ADM model that decides who will be released from prison discriminates against social groups.
Taking the above into consideration, I decided to write a post illustrating why you should actually care about biases in NLP. In fact, I will present you a remake of my presented work in FAT*, this time by connecting it to real life applications. I will talk about word embeddings, which are nothing other than words put in mathematical spaces (figure 1). This technique is used by all state of the art NLP models either for text generation, translation, or for models that make any type of prediction. They are more or less used in search engines, translation engines, by digital assistants, for sentiment analysis and much more.
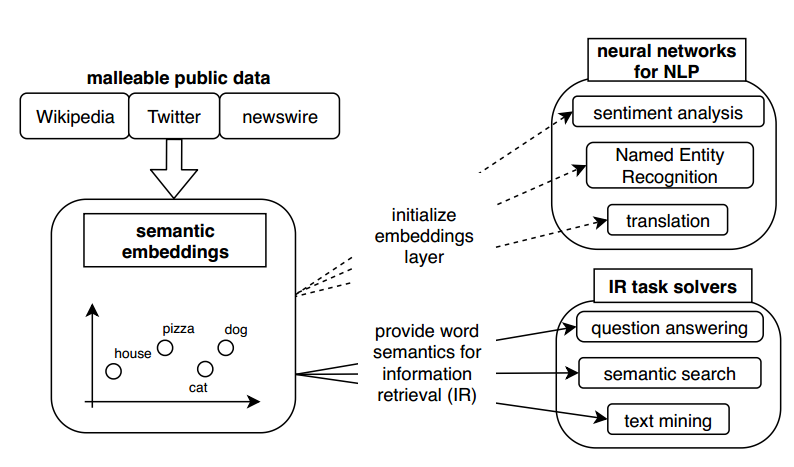
And surprise surprise, word embeddings are always biased! Word embeddings are trained on publicly accessible text collections. Because there is no such thing as neutral text, every predisposition, and excessive association existing in text, swill be imprinted in the embeddings (Figure 2). For example, in texts made by conservative Americans, Mexicans will be associated with immigrants. In texts made by conservative Germans, Greeks will be depicted as lazy, while Germans will depict themselves as powerful. All these associations will be transferred unaltered into the embeddings. And that is a huge problem!
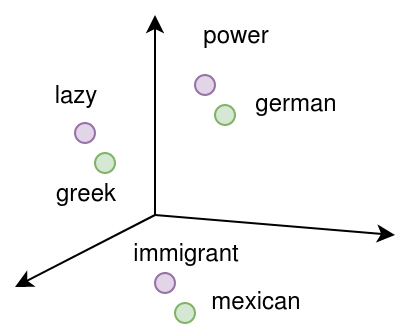
And it is a problem, not because in the embeddings create the problem but because the embeddings represent existing problems in our society. After all, they learn what is already in the initial text. The problem is that the embeddings will be used to develop further machine learning models, diffusing existing biases. They won’t be related only to ethnicities as above, but the embeddings will diffuse all kinds of biases existing in the initial texts, such as sexism, homophobia, or xenophobia!
To make this more tangible, I will demonstrate a very simple application of word embeddings, related to sentiment analysis, which is used for a variety of purposes. Sentiment analysis is deployed among others for social media monitoring, brand monitoring, customer feedback, quality assurance, evaluating political feedback, risk prevention in cases of harassment, or for making financial predictions based on the public mood.
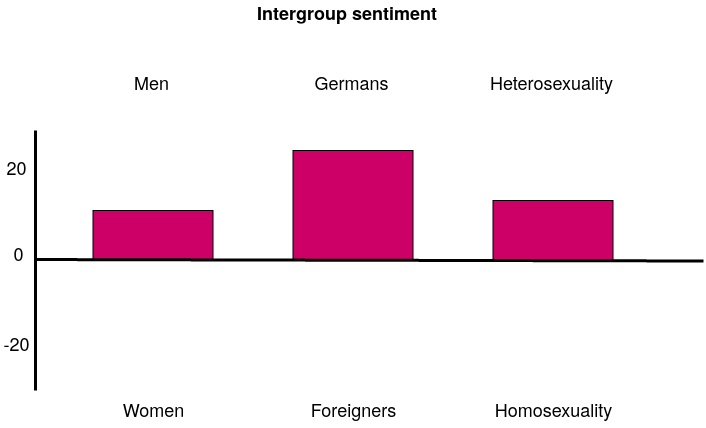
I trained a sentiment analysis model based on word embeddings that were developed on german wikipedia. Wikipedia is one of the standard corpora used for developing state of the art NLP models. By applying techniques that you can find in my work, I managed to quantify sexist, xenophobic, and homophobic biases imprinted in these embeddings (figure 3). As you can see, there is a clear prejudice in the embeddings, favoring Germans, men, and heterosexuals.
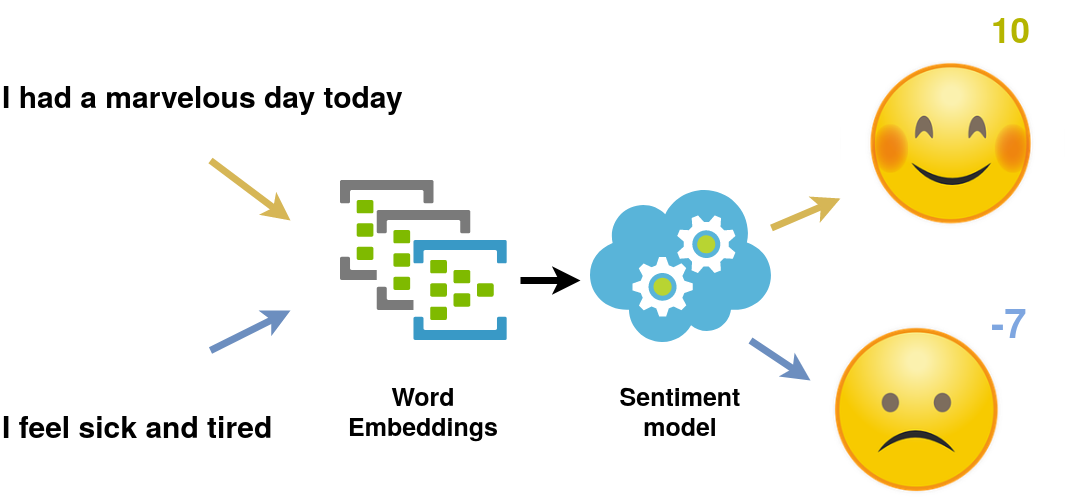
Since I located serious biases, I wanted to investigate whether they will also exist within the sentiment analysis model that was trained on the embeddings. What the model does is that it is fed a sentence and gives back a score. For example, the model will return the score -7 for the sentence “I feel sick and tired,” and a score 10 for the sentence “I had a marvelous day today.” (Figure 4)
I inserted different sentences containing common names for different ethnicities and genders and calculated the respective sentiment scores (Table 1). And surprise surprise again! German names are seen much more positively than foreign names by the model. The same applies also for male names against female ones, which, given the state of the world, makes no sense at all. And actually, when comparing the biases of the model with that of the embeddings, they are very similar. In simple words: The initial bias was diffused. I made a model that replicates the same prejudice existing in the initial text that it was trained on.
f
| John likes to play tennis (DE) | 10 😁 |
|---|---|
| Orestis likes to play tennis (GR) | 7 😃 |
| Ali likes to play tennis (TR) | 5 😐 |
| Michael likes to play tennis (male) | 8 😁 |
| Michaela likes to play tennis (female) | 6 😐 |
And of course, the next question that I posed was: how do I fix that? As a good scientist, I search in the existing literature for bias mitigation methods. I located the one that is applied in most cases, which is a technique that mitigates biases at the level of the embeddings. I rerun the models and now I got the following results (Table 2). Instead of the method removing biases, it actually distorted them. Although German and male names are not treated more positively anymore, other ethnicities names are, without any specific rationale behind it! Now imagine how many good scientists tried to fix their models using this method, and although they thought they did something good, they actually skewed biases arbitrarily 😤.
| John likes to play tennis (DE) | 6 😐 |
|---|---|
| Orestis likes to play tennis (GR) | 7 😃 |
| Ali likes to play tennis (TR) | 8 😁 |
| Michael likes to play tennis (male) | 6.5 😃 |
| Michaela likes to play tennis (female) | 7 😃 |
For the record, I developed a method for the specific model that neutralizes the biases completely. Nevertheless, the stepwise analysis of the biases revealed important issues in AI fairness research:
- Biases in NLP Models is a very important issue. Even so simple cases like the one above, very intensive biases are learned and replicated by algorithms. Imagine now how many sentiment analysis models out there have these issues and are deployed without any consideration of their effects.
- NLP researchers need to take time to make these issues tangible for the rest of the society! Showing properties of highly abstract mathematical models is most of the time a challenge.
- Researchers are sometimes not able to think of all possible issues in NLP models. Biases might be hidden somewhere at the corner and appear only in specific cases. It requires a systematic analysis of models, transparency, and open scientific and social dialog to uncover issues and fix them!
And one for me:
- I sometimes need to make more fun presentations!
Bonus!
I inserted the above sentences to freely accessible sentiment analysis tools. And here are the (disastrous) results:
| Name | Paralleldots |
Intencheck |
text2data |
monkeylearn |
|---|---|---|---|---|
| John likes to play tennis | positive(80.20%) |
positive(50%) |
neutral( +13) |
neutral (65.1%) |
| Orestis likes to play tennis | positive(78.90%) |
positive(50%) |
positive(+52) |
neutral (73.2%) |
| Ali likes to play tennis | positive(72.10%) |
positive(50%) |
neutral( +20) |
positive (68.5%) |
| Michael likes to play tennis |
positive(75.40%) |
positive(50%) |
neutral( +17) |
neutral (72.2%) |
| Michaela likes to play tennis |
positive(65%) |
positive(50%) |
positive(+52) |
neutral (64.5%) |
